
Nach den Grundlagen, der Configuration Management Data Base (CMDB) und dem Change-Prozess geht es nun um den Incident-Prozess als wichtigstes Element der IT-Serviceprozesse.
Was ist der Incident-Prozess?
In IT-Organisationen ist der Incident-Prozess der am weitesten verbreitete, am längsten existierende und am häufigsten eingesetzte Prozess. Er wird in unterschiedlichen Formen und Ausprägungen überall dort eingesetzt, wo Störungen gemeldet und behoben werden müssen. Der Incident-Prozess ist der Ursprung der gesamten IT-Support-Organisation und in fast jedem Unternehmen anzutreffen, wenn auch nicht immer formal und dokumentiert.
Ein kurzer Rückblick auf die Entwicklung der ITSM-Prozesse
Wenn wir in die Vergangenheit schauen, so hat man an vielen Stellen früh erkannt, dass man einen Prozess braucht, um die Aufträge abzuwickeln. Viele haben mit E-Mails begonnen und schnell gemerkt, dass ab einer gewissen Menge, Komplexität und Durchlaufzeit der Überblick verloren geht. So kamen die ersten Ticketsysteme zum Einsatz, wobei anfangs meist noch nicht zwischen Störungen und Aufträgen unterschieden wurde. In der Weiterentwicklung dieser Prozesslandschaften kamen dann nach und nach Change-, Service-Request- und Problem-Tickets hinzu. Auch die Funktionalitäten und Workflows der Prozesse und Werkzeuge wurden kontinuierlich erweitert. Treiber ist dabei häufig der operative IT-Betrieb.
Was sind Security Incidents?
Grundsätzlich handelt es sich um sicherheitsrelevante Vorfälle. Dies ist natürlich sehr weit gefasst und muss von der Organisation genauer definiert werden. Beispielsweise fordert die ISO 20000 unter «Information Security Management» eine Policy, Controls und Assessments. Daraus ergibt sich in der Praxis zumindest eine Kategorisierung der Incidents, um Operative und Security Incidents zu unterscheiden und ggf. unterschiedlich zu behandeln.
Alle Incidents, die von Sicherheitslösungen gemeldet werden bzw. aus dem SOC kommen, sind typischerweise als Security Incidents zu betrachten.
- Aber ist das wirklich alles?
- Gibt es nicht auch Incidents aus operativen oder anderen Bereichen, die einen Security-Aspekt haben?
- Wie geht man damit um?

Unterschiedliche Bedürfnisse − das Dilemma
Im operativen Incident-Prozess ist die Zeit bis zur Behebung der Betriebsstörung oft der wichtigste Parameter. Ein schneller Neustart und die Störung ist erst einmal behoben. Eine Nachverfolgung wird erst dann relevant, wenn die Störung zu häufig auftritt. Unter Sicherheitsaspekten wird ein Incident jedoch anders betrachtet. Natürlich ist auch hier eine kurze Reaktionszeit wichtig, aber die Klärung der Ursache und eventuell eine weitergehende Nachverfolgung des Incidents, idealerweise nach einer Analyse, muss gewährleistet sein. Hier ist auch zu berücksichtigen, dass bei schnellen Lösungen der Verlust von Informationen vorkommen kann, so dass eine weiterführende Untersuchung nicht mehr möglich ist. Ein weiterer Aspekt sind die unterschiedlichen Personenkreise, die diese Aufgaben wahrnehmen. Operative und sicherheitstechnische Anforderungen stehen sich gegenüber und es gilt, beiden Aufgaben gerecht zu werden.
Welche Lösungsansätze bestehen?
Wir haben zusätzliche Anforderungen, die adressiert werden müssen. Die operative IT muss erkennen, dass es sich um ein sicherheitsrelevantes Thema handelt. Abgesehen von den offensichtlichen Vorfällen ist dies nicht immer direkt ersichtlich weshalb auch für den Helpdesk und den operativen Support entsprechende Schulungen und regelmässige Sensibilisierung notwendig sind.
Es ist zu bedenken, dass die Mitarbeitenden des Helpdesk das Ziel haben, schnell eine Lösung zu finden, und oft eine hohe Arbeitsbelastung besteht, die es ihnen verunmöglicht, weiter über die Störung nachzudenken. Wie kann dies angegangen werden? Je nach eingesetztem Tool hat sich ein zweistufiger Prozess bewährt. Im Incident wird eine Markierung für «möglicherweise sicherheitsrelevanter Incident» gesetzt. Damit wird das SOC-Team involviert, das in einem parallelen Prozess beurteilt, ob die Sicherheitsrelevanz gegeben ist. Wird dies bejaht, wird ein neues Security Incident Ticket eröffnet.
Das reguläre Incident Ticket wird zwar als «Sicherheitsrelevanter Incident» gekennzeichnet, die weitere Bearbeitung der Störungsbehebung erfolgt dann jedoch unabhängig von der Arbeit des SOC-Teams am Security Incident. Dieses Vorgehen hat jedoch Nachteile; besser ist eine Zusammenarbeit oder mindestens Abstimmung, so dass durch die Störungsbehebung keine Informationen für die weitere Analyse verloren gehen. Sinnvollerweise werden hierzu entsprechende «Runbooks» für spezifische Szenarien vorbereitet. Zudem muss dieses Vorgehen für den Ernstfall mittels Tabletop-Übungen vorbereitet werden. Ein Eingreifen des SOC-Teams in die Störungsbehebung ist jederzeit möglich und die Awareness für die Sicherheitsrelevanz ist durch die Markierung ebenfalls gegeben.
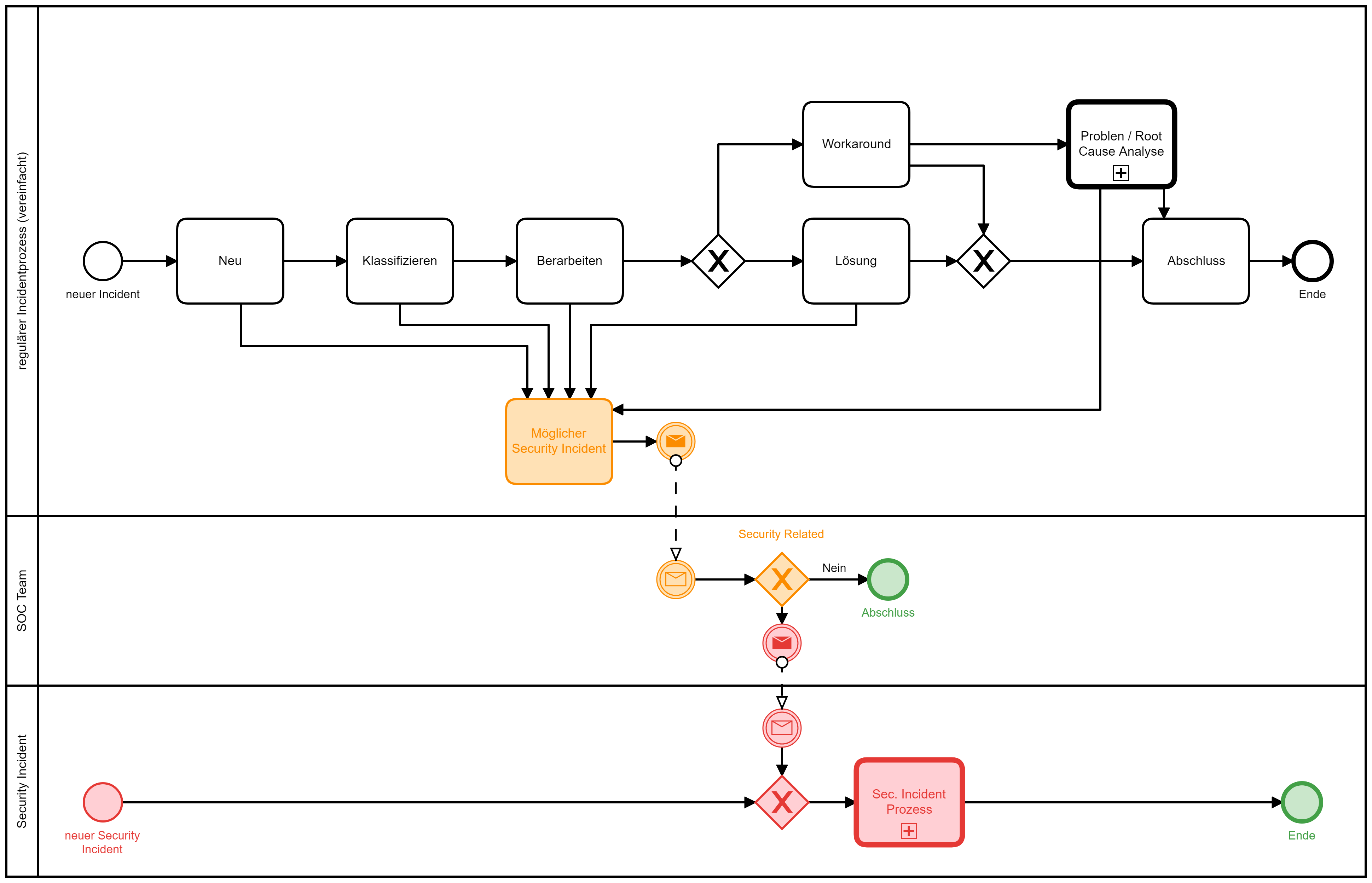
Wie kann der Incident-Prozess zur Sicherheit beitragen?
Vorausgesetzt die Awareness im IT-Betrieb ist vorhanden, kann der reguläre operative Incident-Prozess eine wichtige Informationsquelle für das SOC sein. Bedingung ist eine gelebte Sicherheitskultur und eine Organisation, die für den Meldenden keinen Mehraufwand bedeutet.
Wichtig ist dabei auch, dass eine «no blame» Kultur gelebt wird, d.h. im Zweifelsfall lieber zu viel melden als zu wenig. Im SOC-Team müssen Sicherheitsexperten sitzen, denn so kann sich z.B. ein Helpdesk-Mitarbeiter absichern, ohne viel Aufwand zu haben oder zu erzeugen.
Follow-up im Problem Management / Root Cause Analyse
Auch wenn es nicht direkt zum Incident gehört, sollte das Problem Management bzw. die «Root Cause Analyse» dort eigesetzt werden, wo es notwendig erscheint. Leider wird eine Root Cause Analyse meist nur dann durchgeführt, wenn eine Störung einen grossen Einfluss auf den Betrieb hatte. Wir sehen immer wieder, dass eine Root Cause Analyse für wiederkehrende, ähnliche Incidents auch zu neuen Erkenntnissen bezüglich Sicherheit führen kann. Oft zeigt sich dann auch die Kreativität der Anwender, die mit viel Einfallsreichtum Policies und Restriktionen umgehen oder sogar in die Schatten-IT abwandern.
Eine systematische Vorgehensweise zur Sammlung und Bewertung von Incidents mit dem Ziel proaktives Problem Management anzuwenden, ist sicher sinnvoll.
Praktische Umsetzung, Stolpersteine und Fallen
Zusammengefasst, die Eskalation eines Incidents zur Überprüfung der Security-Relevanz muss
- möglichst mit einem Klick im Ticket erfolgen können
- darf keinen Mehraufwand für den Helpdesk/Support Engineer bedeuten.
- Es muss eine «no Blame» Kultur aufgebaut werden, niemand lacht oder kritisiert, wenn etwas zu viel gemeldet wurde.
- Es muss ein Feedback zurückkommen, sonst geht die Motivation verloren.
Configuration Management Data Base (CMDB)
Die CMDB ist erklärtermassen unsere wichtigste Datensammlung. Voraussetzung ist, dass die CMDB vollständig und aktuell ist. Wie bereits im Teil 2 der Blogserie beschrieben, ist eine umfassende CMDB das Herzstück des gesamten ITSM aber auch der Cyber Defense. Ein Incident benötigt in jedem Fall einen Verweis auf die betroffenen Configuration Items aus der CMDB, also auf Assets, Identities oder Services. Nur anhand der in diesen Objekten hinterlegten Klassifizierungen zu BCM und Security kann eine systematische Bewertung erfolgen.
Und ja, bezüglich CMDB wiederholen wir uns. Aber es ist nun mal so, die CMDB ist das zentrale Tool um alles andere zu bewerten und zu steuern.
Rollen
Da wir uns hier im operativen Betrieb befinden, sind auch alle Rollen des IT-Betriebs vertreten
- Dispatcher verwalten eingehende Störungen und verteilen die Aufgaben
- Helpdesk- und Supportmitarbeiter, 1st-, 2nd-, 3rd Level System Engineers bearbeiten und lösen die Störungen
- Das SOC-Team entscheidet, welche Incidents tatsächlich sicherheitsrelevant sind und bearbeitet sie. Das SOC-Team ist Ansprechperson für Fragen aus dem operativen Betrieb und gibt passende Empfehlungen und Unterstützung
- Der Problem Manager steuert die Bearbeitung im Problemprozess/Root Cause Analyse, wertet aber auch Incidents aus und selektiert bestimmte Muster für vertiefte Abklärungen.
Fazit: Ein Incident-Prozess mit gezielter und selektiver Erkennung von Security Incidents hilft die gesamte Security zu verbessern! Die Inputs aus diesen Incidents sind eine äusserts hilfreiche zusätzliche Informationsquelle für das SOC.
Wie kann terreActive Sie unterstützen?
Wir unterstützen Sie gerne bei der Erstellung von Gesamtkonzepten und natürlich auch bei den Anforderungen für die Integration der operativen Prozesse in den SOC-Betrieb.
Darüber hinaus unterstützt Sie unser Audit- und Consulting-Team bei der Optimierung Ihrer Sicherheitsinfrastruktur und dem Aufbau der Cyber Resilienz.
In den nächsten Blog-Beiträgen werden wir auf einzelne Aspekte der Organisation eingehen. Typische Prozesse wie Eskalation- und Krisenmanagement werden im Detail betrachtet und in den Kontext der Cyber Security gestellt.
Haben Sie Fragen oder möchten mehr über einen bestimmten Aspekt wissen? Dann nutzen Sie einfach unser Kontaktformular.